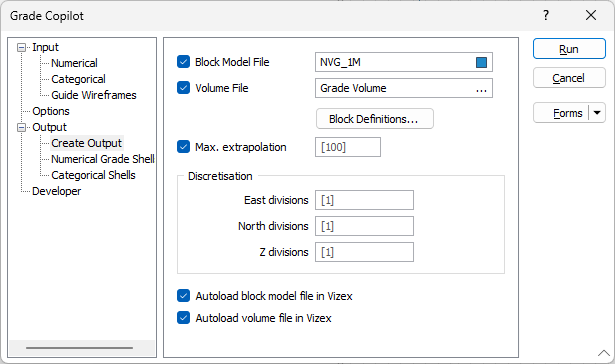
Create Output
On the Output tab of the form, you have the option to create a Block Model file and/or a Volume file as the output. Volume files can be useful as they provide an efficient way to store and display the data. If you have a large number of blocks you may find it easier to display the data as a volume file. Volume files can currently only store numerical data so estimates of categorical data will not be written to the Volume file. If the model type is Categorical only you will not have the option to produce a Volume file.
Block Model File
Enter the name of the Block Model File that will be created.
Volume File
Enter the name of the Volume File that will be created. If the Input data is only Categorical data and Numerical data is not selected, the Volume File option will be inactive.
Block Definitions
Click the Block Definitions button to open the form to define the extents of the model and the resolution (block size). See Block Model Extents for more information on how to use complete the required information. See Discretisation below for more details on selecting appropriate block sizes.
Maximum extrapolation
Optionally enter the maximum distance that estimates are extrapolated from the input data. Block centroids that exceed the maximum extrapolation distance will not be created.
Discretisation
Specify the number of divisions in the East, North, and Z directions. These are integer values that control the number of discrete points to be queried in each direction within each block. The values of all the discretised points are then averaged to estimate a single value for the block, which is written to the output file.
For example, if you choose 2 East divisions, 2 North divisions, and 2 Z divisions, the application will obtain and average a total of 8 estimates for each block. This can obviously add significant time to the inference process if you have a large number of blocks. It is not advised to use small blocks and high discretisation values because querying so many points will be inefficient and may take a long time. The default is 1 so the only location that will be queried is at the centre of the block.
When choosing appropriate block sizes and discretisation settings it may help to consider the following. The neural network has no information about the size of the block it is trying to infer. It is trained on the data you give it so it attempts to deduce the value that a sample would have at each location it is queried at. It is attempting to make estimates at sample sized support. It is not perfect at this so there is some degree of smoothing, but it is not an averaging technique like kriging or IDW.
As with all estimation techniques, the continuity of the grade and the sample spacing need to be considered when selecting block sizes and discretisation values. For each direction, the lower the continuity of the grade/lithology, the greater the resolution that the model should be queried at in that direction. The greater resolution can be achieved by either using smaller blocks or by increasing the discretisation. The relative settings may depend on the use of the model. Visualisation models may benefit from smaller blocks but there is a long geostatistical bibliography on warnings against relying on estimates of small blocks so beware.
East, North, Z fields
Double-click (or click on the List icon) to select the coordinate fields in the Input file.
Autoload block model file in Vizex
Select the option if you want the block model created by Grade Copilot to be automatically loaded into Vizex.
Autoload volume file in Vizex
Select the option if you want the volume file created by Grade Copilot to be automatically loaded into Vizex.
Note: When autoloading a Block Model via Grade Copilot, the Show Block Edges option for the Block Model Display settings will be set to false.