Rank Kriging
![]()
Use the Rank Kriging option for non-parameteric or distribution free statistics. Your data will be transformed so that it has a uniform distribution (where the probability of each value occurring is equal).
Samples are ranked from lowest to highest. Each observation is assigned a rank. These ranks are then transformed into a percentage value against the number of samples + 1. This means a value of 75 is three-quarters of the way along the data list.
Input Data
On the Input Data tab of the Rank Kriging form, enter (or double-click to select) the name of the input file. If required, define a filter to selectively control which records are processed.
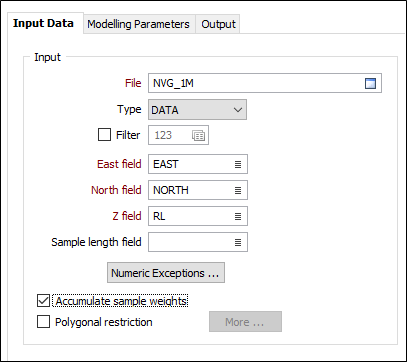
East, North, Z fields
Double-click (or click on the List icon) to select the coordinate fields in the Input file.
Sample length field
Optionally double-click (or click on the List icon) to select the name of a field that contains sample lengths.
If a Sample Length field is specified, per-sample distance weights are calculated as normal, multiplied by the sample lengths, and then rescaled so that they sum to 1. The length of each sample is also written to the verbose report file.
Numeric Exceptions
(Optionally) Use the Numeric Exceptions group to control the way that non-numeric values are handled. Non-numeric values include characters, blanks, and values preceded by a less than sign (<).
Accumulate sample weights
Select this option if you want to keep a running sum of the weight allocated to each input sample for each block estimate, and write the sum of all weights per sample back to the Input file.
An accumulated sum of the weights is useful in showing how much each sample contributed to the resulting model.
Polygonal Restrictions
Optionally, select the Polygonal Restrictions option and click the More button to restrict which points are used in the estimates. For more details, refer to the Polygonal Restriction topic.
Blocks from file
As an alternative to explicitly defining the block size and quantity, select this option to define blocks from a file and specify the file and fields that contain block definitions.
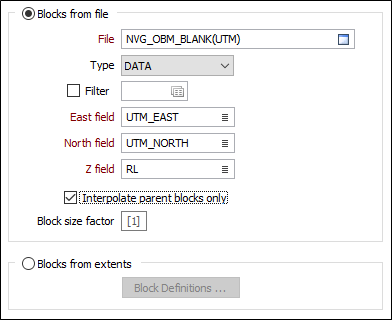
Interpolate parent blocks only
If you are defining blocks from a file, select this option if you want to restrict the process so that it includes parent blocks only.
If the Blocks from File option selected, the function will operate differently depending upon whether it is the first run (when the Output file is created) or a subsequent run (when the Output file is updated). Typically, on the first run, fields are added to the Output file, while the content of those fields are updated on subsequent runs (when the Output file name is copied as the Blocks from File file name). If necessary, fields can still be added on subsequent runs.
Block size factor
The block size factor allows a user-defined block size to be used for the interpolation of the grades to the block model. If specified, the block factor will be a (2, 3, 4, etc.) multiple of the parent block size.
Blocks from extents
Block Definitions
Click the Block Definitions button to define the size of the blocks and the extents within which estimates will be calculated.
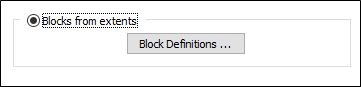
You can also rotate the block model by defining an angle of rotation or using the rotation of a search ellipsoid. See: Block Model Extents
Forms
Click the Forms button to select and open a saved form set, or if a form set has been loaded, save the current form set.
Run
Enter parameters in the Parameters and Output tabs, then click Run to run the function.