What Happens During a Receipt
Processing
Several tasks are performed when results are read from the input file.
Lab repeats and lab splits
If so instructed, Sample Tracker will generate additional sample tags for lab repeats and lab splits. This is done by adding a suffix to the original sample tag. In the case of a lab repeat, the suffix is of the form Rnn, e.g. S7668R1. In the case of a lab split, the suffix is of the form Snn, e.g. S7668S1.
Applying text rules
Some result values may be coded in accordance with the text rules defined for the laboratory. These text rules are used to identify special cases, e.g. results that were below detection limit.
Text rules are used to determine the values for STORE_RESULT and CALC_RESULTthat will be stored in the results table. These values are usually determined by using a calculation based on the lower detection limit.
The rules for any given laboratory are defined via the ST_MD_TEXT_RULE table, for example.
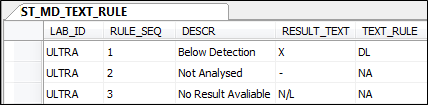
When Sample Tracker encounters a non-numeric value in the result field, it attempts to match the result text to one of the codes defined in the text rules for the laboratory. It then uses the logic associated with the specified text rule to determine the stored and calculated values for the result.
The logic for calculating these values is linked to generic text rule codes, which are stored in the ST_XS_TEXT_RULE table.
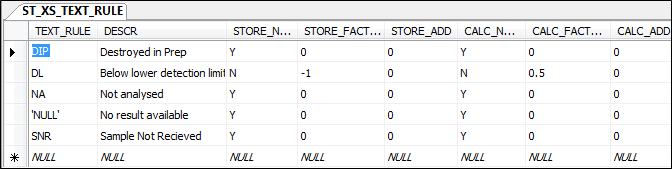
For any given text rule the logic is applied as follows:
- If STORE_NULL is true (Y), no value is stored in STORE_RESULT
- If STORE_NULL is false (N), the value for STORE_RESULTis calculated as follows:
Value = LDL * STORE_FACT_DL + STORE_ADD
where LDL is the lower detection limit.
The same logic is applied to CALC_VALUE, using the constants stored in CALC_NULL, CALC_FACT_DL and CALC_ADD. However, in the case of CALC_VALUE, the final value depends on the outcome of the unit conversion. (See below)
If STORE_NULL and STORE_CALC are both true, then the result record will not be stored.
For example, given the text rules shown in the previous examples, a result value of X (below detection) would be implemented as follows:
- The value of STORE_RESULT is set to the negative of the lower detection limit for the current element/method combination
- The value of CALC_RESULT is set to half the detection limit.
The final value of CALC_RESULT will depend on whether a unit conversion is applied or not.
Upper detection limits are not reported in version 1 of the standard SIF format; however, Micromine Geobank allows more flexibility with regard to input data formats, making it possible to include upper detection limits in the laboratory results.
The column USE_UPPER_DL in the ST_XS_TEXT_RULE table deals specifically with text rules that apply to the upper detection limit. The value of USE_UPPER_DL indicates whether the upper detection limit should be used in calculations, viz:
| Value | Meaning |
|---|---|
| N (or blank) | Use the lower detection limit for calculations |
| Y | Use the upper detection limit for calculations |
Text rules always use the detection limits that are explicitly defined in the header records of the input file. Detection limits cannot be extracted from the result text in the assay data. For example, if the text string >10000 is identified as an upper detection text rule for a given lab (table ST_MD_TEXT_RULE), then the detection limit used in the calculations will be whatever detection limit is defined in the input file; not the value 10000. Similarly, a text value of <0.01 does not automatically imply that a lower detection limit of 0.01 should be used in the text rule.
Unit conversions
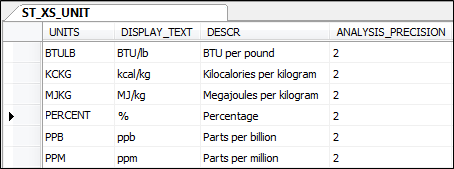
The value of STORE_RESULT is stored "as is" (i.e. using the units of measurement as reported by the laboratory). However, the value of CALC_RESULT is always stored in the same units, i.e. the nominated units for the element. (Nominated units for the various elements are stored in the NOMINATED_UNITS column of the ST_XS_ELEMENT table.) If necessary, the value of CALC_RESULT will be converted to the nominated units, using conversion rules defined in table ST_XS_UNIT_CONVERT.
The logic for every possible conversion must be entered in the unit conversion table. Conversions from ppm to ppb and from ppb to ppm must be defined individually.
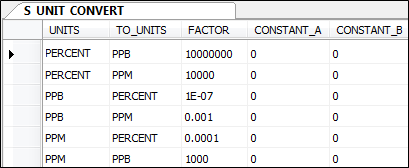
When converting a value from UNITS to TO_UNITS, the new value is calculated as:
Y = (X + CONSTANT_A) * FACTOR + CONSTANT_B
where X is the original result value.
Keep in mind
that any change in the nominated units for an element would basically
invalidate the values of CALC_RESULT in the database and would therefore
require an update of all the records in the ST_RESULT and ST_RESULT_STANDARDtables. This is why it is considered bad practice to store calculated
values in a database. Unfortunately the complexity of result pivot queries
has made it necessary in this specific case.
The word
"PERCENT" (rather
than %) is
used as the units code for percentage in the ST_XS_UNIT table. This
is because the percentage sign can be used as a wildcard in SQL queries.
As a rule, you should avoid the use of special characters in values that
are likely to be included in selection criteria in SQL queries.
Storing the receipt
The following tasks are performed when a receipt is saved:
- General properties are written to the ST_RECEIPTtable.
- Additional samples generated during the receipt (lab checks, lab repeats or lab splits) are written to ST_DESPATCH_SAMPLE.
- Additional standards generated during the receipt (lab standards) are written to ST_DESPATCH_STANDARD.
- Results for standards are written to ST_RESULT_STANDARD.
- Remaining results are written to ST_RESULT.
- Additional combos generated during the despatch are written to ST_DESPATCH.
- If requested, an HTML report is written to the designated folder.
Standards are stored in a separate table because a standard is fundamentally different from any other sample, in that it cannot be linked in any logical way to a sample collected in the field.
Processing multiple lab jobs for the same despatch
Often the laboratory will return partial results in the first lab job and send the rest of the results at a later date. This is not a problem, as Sample Tracker can handle multiple receipts for the same despatch. However, problems may arise if these lab jobs are not processed in the correct chronological order.
Let's assume that the first lab job contains the results for some analyses, while others have been coded with a text rule, e.g. LNR. Depending on the way the text rule has been set up, this may cause a specified value to be stored in the result table along with the LNR code. When the second lab job is processed, the LNR result will be replaced with the latest (TRUE) result. The problem occurs when (for some reason or another) these two lab jobs are processed in reverse order. In that case, the LNR result would overwrite the TRUE result.
Before storing a text rule result, Sample Tracker will first check to see whether a TRUE result exists for the same analysis. If so, it will keep the TRUE result and ignore the text rule result.
Laboratory QC based on field/blind standards
Sample Tracker ignores lab QC analyses performed on standards that were submitted from the field. For example, results of combos that are identified as repeats or splits will be stored for routine or check samples, but not for standards.
Recent changes have introduced an exception to this rule.
When a lab QC combo is identified as a "new request" and is associated with a derived element name (e.g. AuR1, AuR2, etc.), that combo will be treated as "routine" and therefore the results will be stored for standards as well.