Input File Formats
Sample Tracker accepts input from laboratory result files in various formats, some of which are based on the standard interchange format (SIF) concept. You may implement variations on the SIF layout, provided that the basic structure is adhered to. Currently, these implementations include fixed format, Comma Separated Values (CSV) and Extensible Markup Language (XML) files.
File Structure
A typical lab results file consists of two sections: a header section and a data section.
Header Section
The header section consists of a number of lines (records), containing general information relating to the sample receipt (such as the despatch identifier, lab job number, date and comments) as well as details of the analyses performed (i.e. analytes, method codes, units of measure and detection limits).
The requirements for this section are as follows:
- Despatch number, lab job number, receipt date, comments, etc. (if present) must appear in the header section of the file
- Element codes must appear in consecutive fields on a single record
- Lab method codes (one for each element) must appear in consecutive fields on a single record
- Units of measure must appear in consecutive fields on a single record
- Lower detection limits must appear in consecutive fields on a single record
- Upper detection limits must appear in consecutive fields on a single record
The rows containing element, method, units and lower detection limit are compulsory.
In Sample Tracker, analytical details are grouped together in collections known as "combos" (element/method combinations). Each combo consists of an element code, a lab method code, a units of measure code, a lower detection value and (optionally) an upper detection value. Two combos are considered to be identical if the element, lab method, units and lower detection limit are the same.
Data Section
This part of the file comprises a number of records containing the actual analytical results. Each row must contain at least the sample identifier, followed by the results (in the same order as the corresponding combos defined in the element header row). The data section can also contain additional fields, such as sample tag qualifiers.
Format Layouts
No further configuration is required if you are planning to use standard, fixed format SIF files to import analytical results. However, if necessary you may implement variations on the standard SIF layout by defining a new format.
The idea behind a format definition is to tell Sample Tracker where to locate important data in the input file. In other words, a format definition provides various points of reference to be used by Sample Tracker when it decodes the input records.
Customised format definitions are stored in the Sample Tracker database. Two database tables are used for this purpose:
ST_XS_FORMAT
This table contains a list of all your customised format definitions.
| Column | Description |
|---|---|
| FORMAT_ID | An abbreviation used for this format. |
| FORMAT_SEQ | Display order (e.g. in format lists). |
| FORMAT_DESCRIPTION | A short description of the format. |
| FORMAT_TYPE | Either SIF, CSV or XML. The CSV option is used for files that contain the same basic data as a SIF file, but with the field values separated by commas (i.e. not in a fixed format). The XML option is used for XML files. 1 |
| FILE_MASK | A filter used in file dialog boxes (e.g. *.SIF for SIF files). |
Although it is possible to define XML content in other ways, the XML data definition is included in the Sample Tracker format tables for the sake of consistency. The XML implementation is described in more detail later. Note that the XML option is not available in version 7.1.
ST_XS_FORMAT_LAYOUT
This table stores column definitions for the fields that could be present in a customised SIF file format.
| Column | Description |
|---|---|
| FORMAT_ID | Format abbreviation, as stored in ST_XS_FORMAT |
| FIELD_ID | The system name by which this field is known to Sample Tracker. |
| DESCR | Description of the field contents (used for display purposes in the receipt and receipt report). |
| SHEET_ID | In Version 7 and upwards, this field is used to store a default value for fields that do not appear in the input file. (See discussion regarding tag qualifiers). |
| FIELD_SEQ | Display order (e.g. in field lists). |
| FIELD_ROW | The row number, identifying the data record on which this field appears (where 1 is the first record in the file). A value of zero indicates that the field is not present in the input file. (See note under FIELD_COL.) |
| FIELD_COL |
In a fixed format SIF, this value refers to the actual starting position
for the field on the input record (with 1 indicating the first character).
In a CSV format, this value refers to the field index in the record, where
1 is the first field, 2 is the second field, etc. (separated by commas).
A value of zero indicates that the field is not present in the input file. However, if the value is zero and the value of FIELD_ROW is greater than zero, then a default value will be used for this field (as stored in SHEET_ID). |
| FIELD_LEN | In a fixed format SIF, this refers to the actual width of this field in the input record. (This value is not used for CSV files.) |
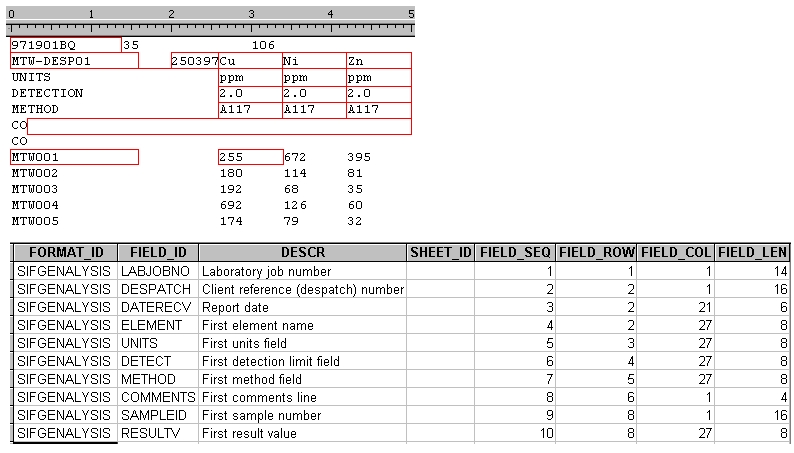
The value in the FIELD_ID column of the format layout refers to the system name of a field. This is a predefined name by which the field is known to Sample Tracker. For example, Sample Tracker looks for the field "DESPATCH" when it needs to retrieve the value of the despatch identifier. Similarly, System fields usually have a specific meaning or function, therefore it is important that they be correctly identified.
The value of FIELD_ROW has particular importance in the case of the SAMPLEID field. This row is assumed to be the start of the data section (in other words, the first record in the file containing analytical results.) Consequently, the row values for the SAMPLEID and RESULTV fields should be the same. All rows preceding the data row are assumed to fall in the header section.
The following system field names are recognised by Sample Tracker:
| Name | Description | Section |
|---|---|---|
| DESPATCH | Despatch identifier | Header |
| LABJOBNO | Lab job number | Header |
| DATERECV | Date of report (string in the format ddmmyy) | Header |
| PERSON | Person processing the receipt* | Header |
| DELIVERY | Delivery method* | Header |
| INVOICE | Invoice number* | Header |
| AMOUNT | Invoice amount* | Header |
| CURRENCY | Currency of Invoice | Header |
| COSTCODE | Cost code* | Header |
| ELEMENT | First element code | Header |
| UNITS | First units code | Header |
| DETECT | First lower detection value | Header |
| UDETECT | First upper detection value* | Header |
| METHOD | First method code | Header |
| COMMENTS | First comment | Header |
| SAMPLEID | First sample tag | Data |
| RESULTV | First result value | Data |
These fields do not appear in a standard SIF file, but can be configured for customised SIF formats. It is possible to define addition fields to cater for special cases, such as sample tag qualifiers.
You do not need to define a format layout if you intend to use only standard SIF files. For Sample Tracker purposes, a Standard SIF File is one for which the format layout is as follows:
| System Name | FIELD_ROW | FIELD_COLUMN | FIELD_WIDTH |
|---|---|---|---|
| DESPATCH | 2 | 1 | 6 |
| LABJOBNO | 1 | 1 | 4 |
| DATERECV | 2 | 21 | 6 |
| ELEMENT | 2 | 27 | 8 |
| UNITS | 3 | 27 | 8 |
| DETECT | 4 | 27 | 8 |
| METHOD | 5 | 27 | 8 |
| COMMENTS | 6 | 3 | 80 |
| SAMPLEID | 8 | 1 | 16 |
| RESULTV | 8 | 27 | 8 |
Here is an example showing the top section of a standard SIF file, as well as the corresponding layout as it would appear in the ST_XS_FORMAT_LAYOUTtable:
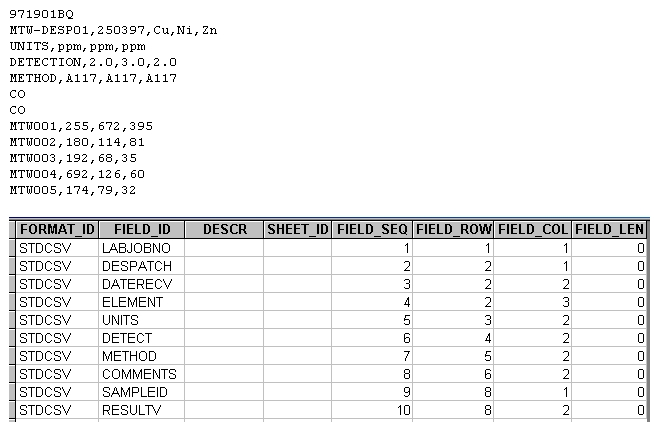
Here is an example of a CSV implementation of the standard SIF format:
Extended format definitions
The above examples implement only the standard system fields. It is possible to extend the format layout for the header section to include some of the other fields recognised by Sample Tracker, e.g. upper detection limits.
It is also possible to extend the field set for the data section. However, the important difference here is that any fields defined in the data section are assumed to be related to the analytical results and will therefore be stored in the results table in the Sample Tracker database.
The data section is assumed to start at the row on which the first sample tag appears, therefore any field that has the same FIELD_ROW value as the SAMPLE_ID field will be treated as data.
One of the most popular extensions in the data section is the use of Sample Tag Qualifiers.